
Your AI ops agent just escalated an incident to the wrong team. The runbook it retrieved was accurate: the mitigation steps for payment-service were current, the alert thresholds matched production, and the linked dashboards loaded correctly. But the ownership record the agent surfaced named Team A, who had transferred the service to Team B six weeks ago. The service catalog updated that record the same afternoon. The agent's context assembly pipeline routes every question through a vector store, while ownership data lives as a structured entity record in a service catalog.
Atlan's 2026 analysis of enterprise AI failures found that context failures (missing, stale, or conflicting information) are one of the leading causes of production AI breakdowns. Treating retrieval augmented generation as a complete context engineering system is the architectural decision that produces these failures.
Context engineering involves intentionally designing every slot in an LLM's context window. RAG is one retrieval primitive within that system, well-suited to semantic document lookup. An agent that draws its entire context from a vector store has wired up one slot out of six, and the remaining five require source systems with entirely different query mechanisms.
What is RAG?
RAG has a precise mechanical definition. At query time, you embed the user's input, run an approximate nearest-neighbor search over a vector index (Pinecone , Weaviate , or pgvector ), retrieve the top-k chunks, and inject them into the prompt. The model generates a response grounded in those retrieved passages.
The pattern works well for unstructured document retrieval at scale. If an engineer asks "what does our authentication service's token expiry policy say?", an embedding over documentation chunks surfaces the relevant passage reliably. Production RAG implementations often add considerable sophistication on top of this core pattern. BM25 sparse retrieval runs alongside dense vectors, reciprocal rank fusion merges ranked result sets, and multi-stage rerankers score passages for relevance before final injection. These techniques improve retrieval precision, but retrieval precision only matters if retrieval is the right tool.
This retrieval primitive isn’t suitable for ownership data. "Which team owns payment-service?" is a lookup against a structured entity record that links a service node to a team node in a typed graph. Embedding the query and running cosine similarity over chunked service documentation may surface a passage that mentions the team, if someone wrote that team name into a document at some point. A structured entity graph returns the authoritative, current record by traversing typed relationships directly.
What is Context Engineering?
Treating context engineering as a synonym for RAG collapses a complex architecture into a single retrieval pattern. Context engineering is the discipline of intentionally deciding what occupies every slot in an LLM's context window: what enters, in what format, from what source, updated on what cadence, and subject to what size constraints. A production context payload is assembled from six distinct source categories, each with its own query mechanism and staleness profile:
- System prompt: behavioral constraints, output format requirements, tool definitions, and role instructions. Static for a given deployment, updated by engineers.
- Structured entity metadata: service ownership, dependency graphs, API configurations, on-call schedules, and tier assignments. Authoritative and current, queried from an entity graph.
- Conversation history: prior turns in the current session, typically compressed with selective summarization to fit within token budgets.
- Retrieved documents via RAG: runbooks, architecture docs, policy references, and knowledge base content. Semantically retrieved from a vector index.
- Tool call outputs: live data fetched at inference time, including API responses, database query results, alert feeds, and CI/CD records.
- Agent working memory: accumulated reasoning state across turns, including tested hypotheses, ruled-out causes, and timeline observations.
Each source category produces outputs with different reliability characteristics. A system prompt updated by a senior engineer carries different authority than a documentation chunk that may reflect last year's architecture. An entity graph record updated when a team transfers service ownership is more authoritative for ownership questions than any passage in a runbook.
The architectural decision in context engineering is matching each question type to the right source, then assembling the payload efficiently within the model's token budget. SingleStore's context engineering analysis describes this as the difference between a system that retrieves documents and one that curates, structures, and evolves the full information payload.
The Taxonomy: Where RAG Sits in the Context Engineering Stack
In a production context payload, RAG occupies a single slot among six, each with a different retrieval mechanism. For example, an incident triage agent assembles its payload from entity_metadata queried from an entity graph, retrieved_docs fetched from a Pinecone index over the runbook repository, tool_outputs pulled from live alert APIs, and working_memory maintained across turns in LangChain state. RAG accounts for the retrieved_docs field:
{
"system_prompt": "You are an incident triage assistant. Treat entity_metadata as authoritative for ownership and dependency data...",
"entity_metadata": {
"service": "payment-service",
"owner": "team-payments-infra",
"tier": 1,
"dependencies": ["auth-service", "postgres-primary", "redis-cache"],
"on_call": "[email protected]",
"last_deploy": "2025-01-14T09:22:00Z"
},
"conversation_history": [
{"role": "user", "content": "payment-service is throwing 500s on checkout"},
{"role": "assistant", "content": "Alert confirms elevated error rate since 09:41 UTC..."}
],
"retrieved_docs": [
{"source": "runbook-payment-service-v3.md", "chunk": "For elevated 5xx rates, check connection pool exhaustion first..."}
],
"tool_outputs": {
"current_alerts": {"metric": "error_rate", "value": 0.34, "threshold": 0.05},
"recent_deploys": [{"sha": "a3f2c1", "deployed_at": "2025-01-14T09:22:00Z"}]
},
"working_memory": {
"hypotheses_tested": ["connection_pool", "auth_service_upstream"],
"timeline": "Error rate spiked at 09:41, 19 minutes after the a3f2c1 deploy"
}
}
A 2025 survey on LLM-based agents from researchers at NUS, Renmin University, and Fudan University formally positions RAG as one component within the broader agent memory and context engineering landscape, intersecting with agent memory, LLM internal memory, and the full context engineering system as a whole.
What Breaks When You Treat RAG as Context Engineering
When a context pipeline routes all queries through a vector store, four failure patterns appear consistently in production.
Stale structured data
A RAG pipeline retrieves documentation that reflects what was true when it was written, not what is operationally true now. Reranking operates on retrieval precision over the indexed content, and stale source data produces wrong answers regardless of ranking quality. Ownership data requires a queryable source that updates when ownership changes, and documentation repositories are generally not kept in sync at that granularity.
Entity relationship traversal
“Which services depend on this database?” routed through a vector store returns passages where an engineer happened to write about the database's consumers. That result set is incomplete if documentation coverage is patchy, outdated if it wasn't maintained, and missing entirely if the dependency was never documented. This question requires a traversal over structured dependency metadata, which a typed entity layer can answer deterministically by following dependency edges directly.
Cross-turn reasoning state
In multi‑step workflows like incident response, re‑retrieving documents on each turn causes previously processed context to crowd out the agent’s evolving incident timeline. Hypotheses, checks, and temporal observations must be maintained in a persistent working memory layer, managed by the agent’s state system (for example, LangChain's ConversationSummaryBufferMemory or an equivalent custom store).
Context window inflation
A naive strategy that injects the top‑20 retrieved passages can consume tens of thousands of tokens on documentation that’s irrelevant to the current reasoning step. Because cost per agent invocation scales with context size, bloated payloads add latency and expense without improving output reliability.
What a Production Context Engineering Stack Actually Looks Like
An AI agent handling incident triage puts all six context slots into production simultaneously, each drawing from a distinct source system matched to its query requirements.
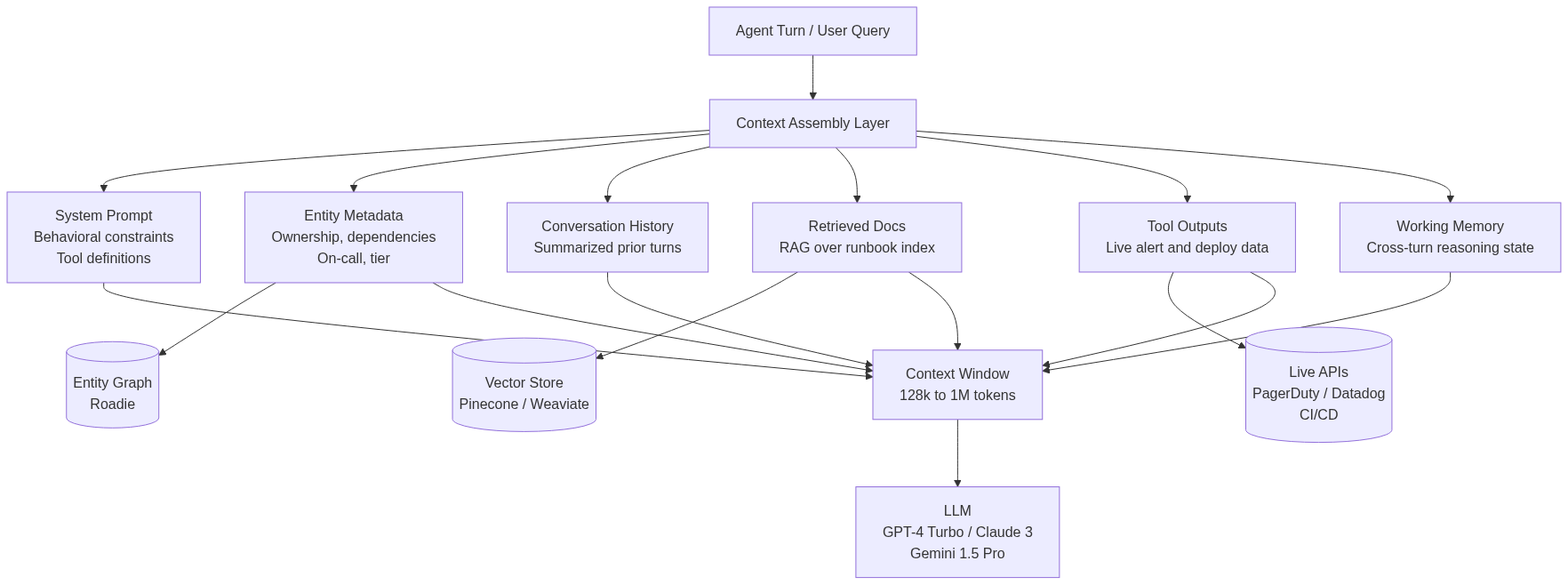
The system prompt carries behavioral constraints, tool definitions, and output format requirements. These load at agent initialization in LangChain or LlamaIndex and remain static across turns.
The structured entity metadata slot is populated by querying an entity graph directly. For the incident agent, that query specifies service=payment-service and returns owner, tier, current on-call, dependencies, and last deploy time. Because this data comes from the same graph that engineers use operationally, the agent inherits its authority and update semantics. Roadie's context engineering platform provides that graph: a queryable record of services, ownership, dependency relationships, and operational metadata that engineers and agents query from the same source. The graph updates when teams update their service records, so the agent always operates on current data. In practice the graph is fed from the operational systems themselves - Git, cloud accounts, PagerDuty, Kubernetes - so ownership and dependency changes surface without a developer remembering to touch a metadata file.
The conversation history slot carries a rolling summary of the current incident session, managed by the agent's memory layer. The retrieved_docs slot runs RAG over a hybrid Pinecone or Weaviate index over the runbook repository, using dense embedding similarity for semantic matching and BM25 for exact term hits, merged via reciprocal rank fusion. The tool_outputs slot carries live data fetched at inference time from PagerDuty , Datadog , and the CI/CD system.
Audit Your Agent's Context Sources Today
Gartner predicts context engineering will appear in 80% of enterprise AI tools by 2028 . To prepare, audit your agent’s context pipeline. For each context slot populated on a turn, answer four questions: what is its authoritative source, such as documentation, an entity graph, a live API, or in memory state? How stale can it be before causing errors? Is the data structured or unstructured? Is it retrieved fresh each turn or carried across turns?
Agents that rely solely on vector databases can accurately answer “what does the documentation say,” but fail on questions about current service ownership, dependencies, or multi-step reasoning state. Those require explicit wiring of additional slots, including entity metadata, tool outputs, and working memory, sourced from systems designed for authority and freshness.
The highest value addition is usually structured entity metadata, including service ownership, dependency graphs, on-call assignments, and API configurations. These change faster than documentation can keep up. Roadie exposes this metadata via a queryable API, making it straightforward to integrate into LangChain or LlamaIndex agents as an additional tool.
Production-grade agents treat context assembly as infrastructure rather than retrieval, matching each question type to a source with the right authority, freshness, and query semantics. Retrieval precision alone is not enough.