
An engineer debugging elevated p99 latency in a payment processing service asks Cursor to trace the issue and propose a fix. The suggestion Cursor returns compiles cleanly, follows the team's Go conventions based on the open files, and appears logically sound. It adds a direct database query to bypass what looks like a slow intermediate abstraction layer.
The suggestion is wrong in three distinct ways. The intermediate layer being bypassed is the team's PCI-scope data access abstraction, required by a compliance contract with the platform team. The downstream service the new code queries belongs to a squad that accepts calls exclusively through an async queue, documented in an API contract that lives in Confluence. The logging Cursor outputs plain strings into a service that has enforced structured JSON since 2023, codified in an architectural decision record written by an engineer who left the company 18 months ago.
Cursor processed the open files, a handful of related functions, and the natural language problem description. The compliance boundary, the ownership edge, the API contract, and the logging convention don't live in source files.
This is the core failure mode of AI coding assistance in production engineering orgs. Outputs that are locally correct and globally invalid because the model operated without system-level context. Expanding the token window doesn't address this, and feeding the AI more source code doesn't address it either. What's absent is structured, queryable metadata about how services relate, who owns what, and what constraints govern each component.
Context Engineering Is Not Prompt Engineering
Prompt engineering occupies the interaction layer of a larger system. It addresses how you word an instruction to improve a model response within a single exchange. Context engineering addresses the architecture of the full information environment that the model operates in, covering retrieval mechanisms, memory systems, structured metadata, entity relationship models, state management, and output formatting constraints.
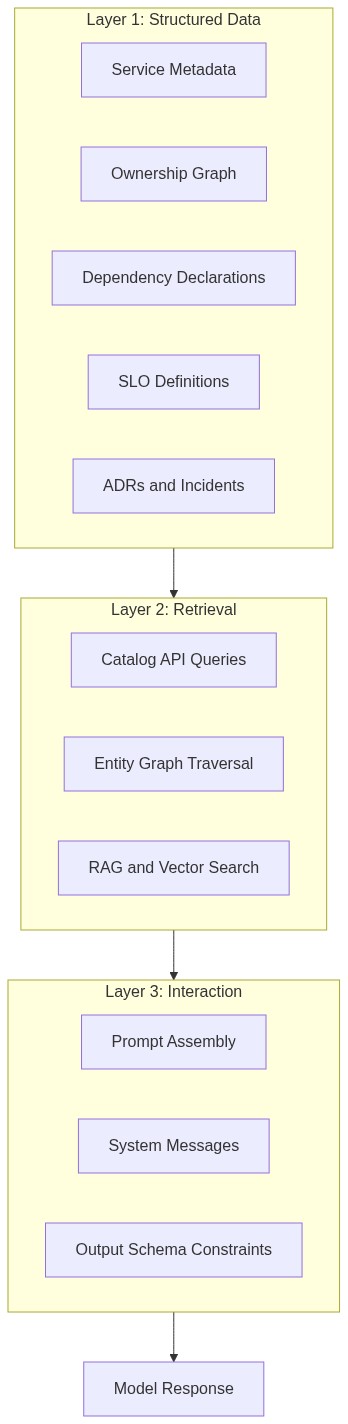
The practical distinction shows up where the work happens. Improving your prompt is a single-file edit. Building context infrastructure requires decisions about data schemas, entity relationship models, API surface areas, retrieval strategies, and update mechanisms. Prompt engineering is one layer of a three-layer stack, and context engineering designs the entire stack:
- Structured data layer: service metadata, ownership graphs, dependency declarations, API contracts, SLO definitions, incident histories, and architectural decision records.
- Retrieval layer: how agents and developer tools access that data at query time, via catalog API queries, entity graph traversals, or vector store lookups.
- Interaction layer: how retrieved context gets injected into the model window at inference time, via prompt templates, system messages, few-shot examples, and output schema constraints.
Most discourse on context engineering addresses layer three. The architectural decisions that determine whether AI tools actually perform in production engineering orgs happen at layer one.
A RAG pipeline over Confluence documentation retrieves text chunks ranked by semantic similarity, and its ceiling is determined entirely by the quality, structure, and currency of the underlying documents. A typed entity graph with declared schemas delivers deterministic query results. When an AI agent asks which team owns payment-processor and what its declared dependencies are, a typed API response gives the agent something it can act on without hedging. Semantic search over unstructured documentation works well for discovery tasks. For AI agents making operational decisions at runtime (routing escalations, scoping incident blast radius, and verifying SLO compliance before a deployment), the two retrieval mechanisms belong to categorically different reliability classes. Build your data layer to support both, with explicit clarity about which class of problem each handles.
What Structured Engineering Context Actually Looks Like
The entities that constitute useful engineering context at the operational layer are services and their declared owners, dependencies with SLO targets, deployment environment definitions, API contracts, past incidents and their resolutions, and architectural decision records. That information exists in most engineering orgs today, but it’s distributed across YAML configs, Confluence pages, Google Docs, Slack channels, and tribal knowledge.
The Backstage entity descriptor format provides a practical starting schema for the structured data layer. A well-formed Component entity gives an AI agent something it can query deterministically:
apiVersion: backstage.io/v1alpha1
kind: Component
metadata:
name: payment-processor
description: Handles charge authorization and settlement for the checkout flow
annotations:
roadie.io/oncall-runbook: "https://wiki.internal/runbooks/payment-processor"
roadie.io/slo-target: "p99 < 200ms, availability > 99.95%"
pagerduty.com/integration-key: "abc123xyz"
spec:
type: service
lifecycle: production
owner: group:payments-team
system: checkout
dependsOn:
- component:ledger-service
- component:fraud-detection
- resource:payments-db
providesApis:
- payment-processor-api
An AI agent triaging a latency incident on payment-processor can resolve the owner to payments-team in one API call, pull the SLO target to assess whether the current p99 violates it, identify ledger-service and fraud-detection as declared dependencies to check, and surface the runbook URL. A RAG pipeline over documentation pages might surface similar information after several retrieval rounds, but a typed entity query retrieves it deterministically in milliseconds, with no ambiguity about which document version applies.
The architectural significance extends beyond any single entity. When ledger-service also has a well-formed descriptor, you can traverse the dependency graph to find which teams own the services that payment-processor depends on, which of those are currently below their SLO targets, and which dependencies changed in the last 24 hours. Those traversals require typed entity relationships with declared schemas, where each edge carries semantic meaning, and each node exposes a queryable API.
How Context Infrastructure Reduces Context Switching in Practice
Incidents are where the cost of manual context assembly becomes most visible. The engineer receiving a PagerDuty alert at 2am has no buffer for multi-tool lookups.
Without context infrastructure, the engineer opens the alerting service in their IDE, switches to Confluence for the runbook, searches Slack for recent incident discussions, and then checks GitHub blame for the last deployer. At that point, they ask Copilot for help. Copilot has access to the open files and the natural language question. It answers without any of the operational context that the engineer spent 25 minutes assembling.
With a queryable context layer, the same engineer issues one API call against a structured entity graph. The response returns the service owner, the last deployment timestamp, the linked runbook, the current SLO status, and the full dependency list. An AI agent receives that same response and uses it to constrain its output. It can flag that a proposed change affects fraud-detection, which is owned by a separate team and is currently operating at 99.96% availability against a 99.95% target. The suggestion is system-aware because the agent's context is system-aware.
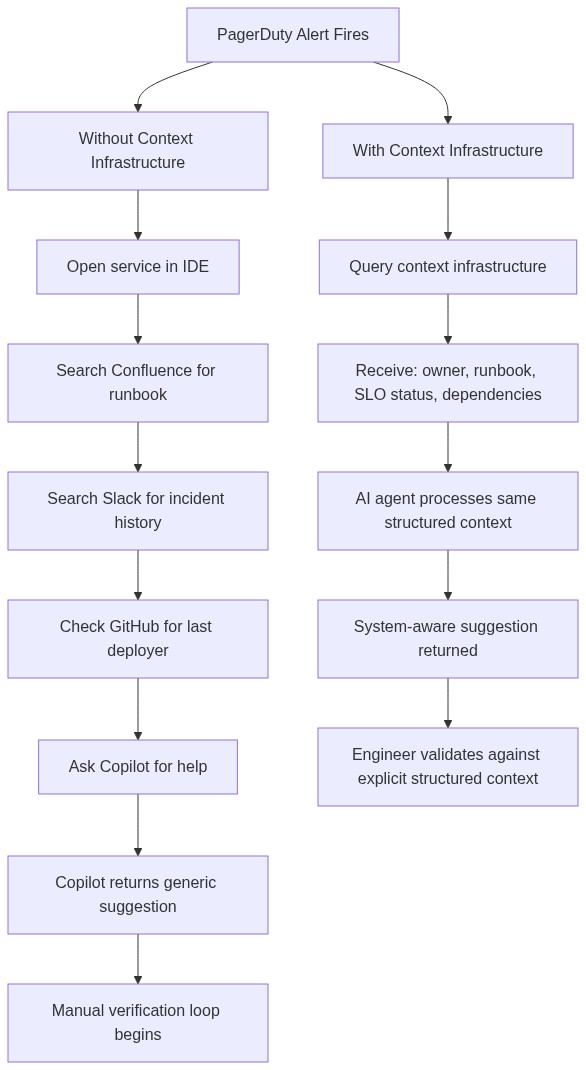
The design decision embedded here matters. If the AI agent fetches the context and routes it silently into the model window while the developer sees only the final suggestion, you've solved the AI's information problem but preserved the developer's cognitive debt problem. The right implementation surfaces the resolved metadata as part of the engineer's workflow, so the structured context is visible to both the person and the agent drawing on it. Engineers who can see what their AI agent knows maintain comprehension, and that understanding deepens over time.
Context infrastructure also eliminates the manual assembly step that causes context switching in the first place. The developer stops acting as the integration layer between their tools, stitching together information from runbooks, Slack, and GitHub before they can form a useful question.
Building Context Infrastructure: What Engineering Teams Should Prioritize
The sequence is important because each layer depends on the one below it. Teams that ship AI features on top of incomplete metadata then wonder why the productivity gains don't materialize are building the wrong way around.
Ship in this order, and don't advance to the next step until each one is complete:
-
Declare entity ownership across your entire service catalog. Every service, library, data pipeline, and API must have a declared
ownerfield pointing to a team or group entity. This is the minimum viable signal for routing, escalation, and impact scoping. AI agents querying your catalog with no ownership data will produce unreliable escalation paths and incorrect blast radius assessments. -
Attach structured operational metadata to those entities. SLO targets, runbook URLs, deployment environment declarations, and dependency lists all belong in schema-defined fields. Free-text description fields are retrieval fodder for RAG pipelines. Structured annotation fields are what AI agents query programmatically. You need both, and they serve different purposes.
-
Expose your catalog via an API that agents can call. A service catalog that only renders in a browser UI is inaccessible to AI agents and automation tooling. A REST or GraphQL catalog API is the connective tissue between your structured metadata layer and any AI capability you want to build on top of it. Without programmatic access, you have a portal, and portals don't compose with agent workflows.
-
Run a coverage audit before adding AI features. If more than 30% of your catalog entities are missing owner, system, dependsOn, or a custom operational annotation (runbook URL or SLO target), context-aware AI features will underdeliver.
Roadie's engineering context platform implements this architecture as a SaaS product built on open standards. Its entity graph exposes typed, relationship-aware service metadata via REST API, queryable by both human engineers and AI agents against the same underlying data layer. Catalog v2 is explicitly designed for this pattern, providing the coverage and programmatic access that make AI-layer features reliable at scale. Teams running custom Backstage installations get the UI, while teams running Roadie get the queryable context infrastructure that those AI features actually require.
Start Here: Run a Metadata Completeness Audit on Your Service Catalog Today
The single most useful action you can take before evaluating any AI developer tooling is a metadata completeness audit on your existing service catalog. Pull every Component entity from your catalog and check four fields: owner, system, dependsOn, and at least one custom operational annotation (runbook URL or SLO target).
For teams running a Backstage-compatible catalog API, the query is straightforward:
GET /api/catalog/entities?filter=kind=Component
Parse the response for entities where spec.owner is empty, spec.dependsOn is an empty array or absent, spec.system is unset, or metadata.annotations contains none of your defined operational fields. Flag any entity missing two or more of those fields as a coverage priority.
If more than 30% of your catalog entities fail that check, fixing metadata coverage will deliver more AI productivity gain than any retrieval or prompt optimization effort. A missing owner field alone means AI agents have no reliable signal for routing, escalation, or impact scoping. A service with no dependsOn declarations means dependency traversal returns an empty graph, making blast radius assessment impossible. If your catalog has above 70% coverage on all four fields, you have the foundation to build context-aware AI features that will actually perform.
Metadata coverage is an engineering problem with an engineering solution: schema enforcement, catalog-as-code with required fields, and ownership reviews in your service onboarding checklist. Ship those fixes, then revisit your AI tooling configuration with a complete data layer underneath it.
Give your engineering team and AI agents the structured context they need to actually ship faster. See how Roadie's engineering context platform works and request a demo.